
Attention: The AI Revolution Catalyst
The revolutionary breakthrough which significantly contributed to development of the AI tools we now use daily dates back to 2017 in the paper "Attention Is All You Need".
You are currently reading the first sentence, aka, sentence number one. Now, I ask that you please think about how you read that previous sentence or how you are reading this sentence now. You don't just process the sentence word by word, forgetting the beginning by the time you reach the end. You grasp context, connections across elements, structure, and meaning across the entire sentence (or phrase). You do this almost instantly, without even trying. However, this is a skill that's learned progressively. For example, a primary goal of education is the progressive improvement of reading comprehension, across increasingly difficult reading material (both in complexity and content). When we are first learning to read, we focus on one reading word at a time (sounding it out, while also knowing what it means, etc.) and this progresses to sentences, paragraphs, and onward. Initially this grasp of the entire context and meaning across all of the writing was not the primary goal. Our attention was narrow at the beginning.
In fact, many of us learn to read initially by sequentially understanding each word in the sentence. However, as we learned and our language skills improved, we no longer focused on the individual words in the sentence, but on the meaning and information conveyed by the input (aka the sentence). A similar situation has emerged in the domain of Artificial Intelligence (AI). For years, AI models trying to understand language did struggle in a similar way to young humans learning to read on a Montaigne novel. AI models would process language like reading a novel through a tiny pinhole, losing track of the plot, not understanding callbacks, or long-context oriented connections.
This level of AI language understanding and sophistication was the reality for sequence modeling tasks like machine translation or text summarization. Due to the state of the field at the time, these tasks were dominated by architectures like Recurrent Neural Networks (RNNs). They processed data sequentially (step by step) which inherently limited their ability to capture long term dependencies, as well as, slowed down training of the Network.
However, in 2017, a paper was published that has been fundamental to the AI developments we see today. Researchers at Google published "Attention Is All You Need" and in turn altered the trajectory of AI. Its core proposal was radical - get rid of recurrence entirely and rely solely on a mechanism called attention to understand relationships across data. The results discussed in the paper suggested that what they were proposing was not just an incremental improvement; it was a paradigm shift.
This paper introduced the Transformer architecture, the foundational blueprint for nearly all the large language models (LLMs) that are seen in the news every day, from ChatGPT and Claude to BERT and T5. It tackled the core problems of older models and unlocked unprecedented capabilities in AI. This article provides a review of the paper, the Transformer, the implications, and reasons why this paper was revolutionary.
The Old Landscape - RNNs and LSTMs
Before the Transformer, RNNs (and their variants like LSTMs) were the standard for handling sequential data (e.g. text). They maintained a hidden state (or "memory") that passed from one step to the next. While it makes sense in theory, this sequential processing created some major obstacles:
- Long-Range Dependency Problem
As sequences got longer, information from earlier steps would get diluted or lost. For example, connecting "the cat... which sat on the mat" was possible. However, a solid understanding of the relationship between the first and last paragraphs of a paper was still extremely difficult (with RNNs).
- Sequential Bottleneck
Processing had to happen one token after another (sequentially). This limited parallelization. For example, you couldn't easily speed things up (by throwing more computing power with GPUs at the problem), making training large models very time consuming (due to the sequential processing). Reducing this sequential computation was a major goal, and parallelization enabled this by reducing the magnitude of sequential processing tasks.
The New Landscape - Attention
Attention mechanisms existed before 2017, but they were typically used in conjunction with RNNs, often to help the decoder focus on relevant parts of the input. However, the important thing outlined by this paper is that the Transformer bets everything on attention alone.
The core idea at the root of everything is to allow the model to directly look at and draw information from any part of the input sequence when processing a specific part, regardless of distance. This is achieved through "self-attention" (also referred to as intra-attention).
At this point, let's take a step back and ask an important question. What is Attention? The definition of attention is "a selective narrowing or focusing of consciousness and receptivity" and "the act or state of applying the mind to something". However, in a less formal way it can be best described as the thing which is selected for narrow focus. This relaxed definition makes the topic more malleable for discussion and consideration from various perspectives. It could be the project at your work that get the most resources and consideration, or the part of a sentence we are reading at each second when engrossed in a great book. In terms related to AI, let's imagine a model is tasked with translating the sentence "The cat sat on the mat" into French ("Le chat s'est assis sur le tapis"). When generating "assis" ("sat"), the model needs to heavily attend to (or put attention on) "sat" but potentially elsewhere too (e.g. "cat"), in order to get the grammar right.
The Transformer paper formalizes this, with the concepts of Queries (Q), Keys (K), and Values (V). Which are all vectors derived from the input embeddings.
Query (Q) - Represents the current token/position being focused on (e.g., the position where you're trying to predict the next word).
Key (K) - Represents all the tokens in the sequence that you could potentially pay attention to. Each key is associated with a specific token.
Value (V) - Also represents all the tokens in the sequence, but these hold the actual information/features you want to potentially aggregate.
Now that we have a preliminary understanding of the key concepts underpinning the the attention mechanism, let's review the steps in the process and how they work.
- Calculate Scores
For your current Query, compare it to every Key in the sequence. This comparison (often a dot product) generates a score indicating the relevance or compatibility between the Query token and each Key token.
- Normalize Scores (SoftMax)
Convert these raw scores into probabilities (weights) that sum to 1. A higher weight means a token is more relevant to the Query.
- Weighted Sum of Values
Multiply each Value vector by its corresponding weight and sum them up. The result is an output vector that blends information from across the sequence, heavily weighted towards the most relevant parts identified by the Q-K comparison.
The Transformer uses a very specific kind of attention called "Scaled Dot-Product Attention". The "scaling" (dividing the Q-K dot product by the square root of the dimension of the keys) is a crucial detail because it helps stabilize gradients during training, especially for large dimensions.
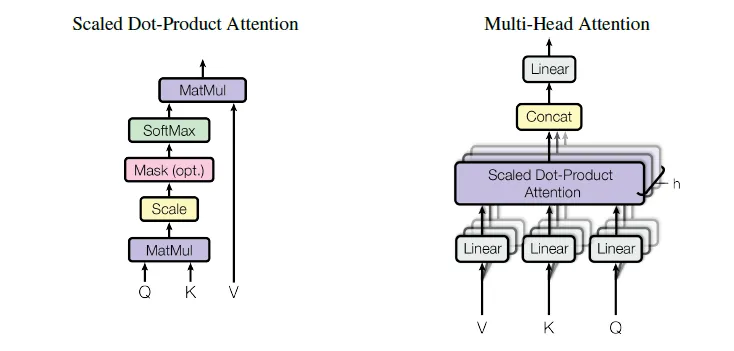
Multi-Head Attention
As seen in the original paper, the Transformer doesn't operate by just calculating attention one time (using a scaled dot-product attention mechanism). It utilizes a multi-head attention mechanism instead, meaning that rather than only having one set of Q, K, V projections, it has multiple sets (e.g., 8 or 12 "heads").
- The original Q, K, and V are linearly projected into multiple lower dimensional versions, one set for each head.
- Scaled dot-product attention is performed in parallel for each head.
- The outputs from all heads are concatenated and linearly projected one final time to produce the final output.
Why is this useful? Each head can learn to attend to different types of relationships or information in different "representation subspaces." One head might focus on syntactic dependencies, another on semantic similarity, another on positional information. It allows the model to capture a richer mix of connections simultaneously.
The Transformer Architecture
The paper explains that the Transformer architecture is an encoder-decoder model. This architecture did exist before transformers (in RNN based models like LSTMs) as it was common for sequence-to-sequence (seq2seq) tasks like machine translation, but the transformer revolutionized how these parts were built. Overall, this two part model is composed of the encoder, which reads the input sequence and encodes it into a context representation, as well as, the decoder which generates the output sequence (step by step) using that aforementioned context.
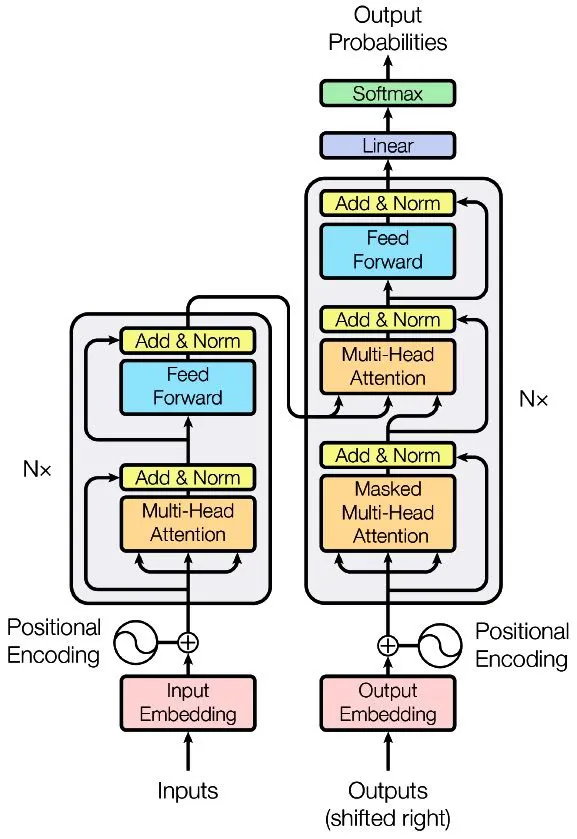
Encoder
The encoder reads the input sequence and generates a context representation. The encoder is a stack of identical layers and each layer has two main sub-layers.
- A Multi-Head Self-Attention mechanism (where Q, K, and V all come from the output of the previous encoder layer).
- A simple, position-wise fully connected feed forward network (FFN), which is two linear transformations with a ReLU activation in between: FFN(x) = max(0, xW1+b1) W2+b2
This is applied independently to each position. Also, residual connections and layer normalization are applied around each sub-layer (crucial for training deep networks effectively).
Decoder
The decoder generates the output sequence one token at a time (auto-regressive). The decoder is also a stack of identical layers, but each layer has three sub-layers.
- Masked multi-head self-attention, which is similar to the encoder, but with "masking" applied. This prevents positions from attending to subsequent positions (i.e., prevents looking ahead at the answer during training/generation), preserving the auto-regressive property.
- Encoder-decoder attention, which is where the decoder looks at the input sequence. The queries (Q) come from the previous decoder layer, while the keys (K) and values (V) come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence.
- Position wise fully connected FFN (identical to the encoder's). Residual connections and layer normalization are again used and are applied around each sub-layer (for effective deep network training).
Embeddings and Position
However, there are still two other critical elements (embeddings and positional encodings) which significantly contributed to the Transformer's revolutionary effectiveness.
- Embeddings
Like many Natural Language Processing (NLP) models, the transformer converts input tokens (words or partial words) and output (contextual representation) tokens into vectors of a fixed dimension (dmodel).
- Positional Encodings
Since self-attention itself doesn't inherently know the order of words (it just sees relationships), we need to inject information about the position of each token. The paper proposed using sine (sin) and cosine (cos) functions of different frequencies. These positional encoding vectors are added to the input embeddings at the bottom of the encoder and decoder stacks. This gives the model a sense of relative and absolute positions.
The Impact
The Transformer has had a large impact on the AI landscape ever since it was first introduced by the researchers at Google. It delivered state of the art results (at the time of its release) using a novel and sophisticated architecture, fundamentally altering the direction of the AI field and shifting people's views about the landscape.
- It significantly outperformed existing models on machine translation benchmarks. Exhibiting state of the art performance, and setting the new standard for machine translation tasks.
- By eliminating recurrence, computations within layers could be heavily parallelized on GPUs/TPUs, drastically reducing training times compared to RNNs for equivalent model sizes. This unlocked the era of massive models trained on massive datasets, due to the benefits of parallelization.
- Self-attention creates direct paths between any two tokens, making it much easier to model long-distance relationships. Effectively providing a solution for handling the long-range dependency problem.
- Its flexibility and capabilities proved to be exceptional, and different parts of the architectural foundation became the basis (in the subsequent years) for other influential models (BERT, T5, GPT, BERT variants, GPT variants etc.).
- BERT: Primarily uses the encoder stack for tasks requiring deep bi-directional context understanding (question answering, sentiment analysis).
- GPT: Primarily uses the decoder stack for generative tasks, predicting the next token based on previous ones.
- T5 and BART: Use the full encoder-decoder architecture for sequence-to-sequence tasks.
- Other: Beyond just text, the core ideas were adapted for Vision Transformers (ViT) for image classification and Speech Transformers for audio tasks, demonstrating the generality of the attention concept.
The Attention Revolution Continues
In conclusion, the Attention Is All You Need paper did more than just introduce a new model, it introduced a new way of thinking about sequence modeling. It showed that direct, attention-based connections could entirely replace the need for sequential processing, overcoming fundamental limitations of previous approaches.
The ability to capture long-range dependencies effectively and the massive parallelization it enabled are twin engines [contributed from this paper] that greatly helped drive the progress in AI. Nearly every sophisticated language (and increasingly, vision and audio) model owes its existence to the core principles laid out in this paper from 2017. After learning about how to teach machines how to "pay attention" the world of AI shifted, and hasn't been the same since.
Code Implementation
This code block below is a simplified implementation of a Transformer encoder in PyTorch. It includes the core components:
- Multi-Head Attention: The attention mechanism that allows the model to focus on different parts of the input sequence
- Feed Forward: The fully connected layers that process the attention outputs
- Positional Encoding: Adds position information to the embeddings
- Encoder Layer: Combines attention and FFN with residual connections
- Transformer Encoder: The complete encoder with multiple layers
The code includes comments to help with understanding each component's function. It demonstrates how these parts work together to create the transformer architecture that powers modern NLP models.
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.query = nn.Linear(d_model, d_model)
self.key = nn.Linear(d_model, d_model)
self.value = nn.Linear(d_model, d_model)
self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.shape[0]
# Linear projections and reshape for multi-head attention
q = self.query(q).view(batch_size, -1, self.num_heads,
self.head_dim).transpose(1, 2)
k = self.key(k).view(batch_size, -1, self.num_heads,
self.head_dim).transpose(1, 2)
v = self.value(v).view(batch_size, -1, self.num_heads,
self.head_dim).transpose(1, 2)
# Scaled dot product attention
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
# Apply mask if provided (for causal attention)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# Attention weights and context
attention = torch.softmax(scores, dim=-1)
context = torch.matmul(attention, v)
# Reshape and project output
context = context.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model)
output = self.out(context)
return output
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(self.dropout(torch.relu(self.linear1(x))))
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Self-attention with residual connection and layer norm
attn_output = self.self_attention(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# Feed forward with residual connection and layer norm
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, d_ff,
num_layers, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, dropout)
self.layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
# Get embeddings and add positional encoding
x = self.embedding(x)
x = self.pos_encoding(x)
# Process through encoder layers
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
# Create positional encoding matrix
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
(-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
# Use Case Example
def create_transformer_model(vocab_size=10000, d_model=512,
num_heads=8, d_ff=2048, num_layers=6):
model = TransformerEncoder(
vocab_size=vocab_size,
d_model=d_model,
num_heads=num_heads,
d_ff=d_ff,
num_layers=num_layers
)
return model